Java并发
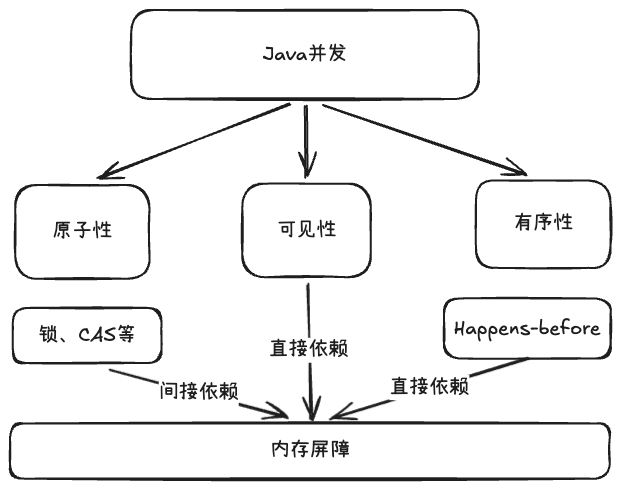
- 原子性:一个或多个操作,要么全部执行完且中间不被任何干扰,要么一个都不执行。
- 可见性:一个线程对共享变量的修改,其他线程能立刻看到。
- 有序性:程序执行的顺序,按照代码的书写顺序来。
Java内存模型
[!info] JMM 主要解决可见性、有序性,基本保证原子性操作。
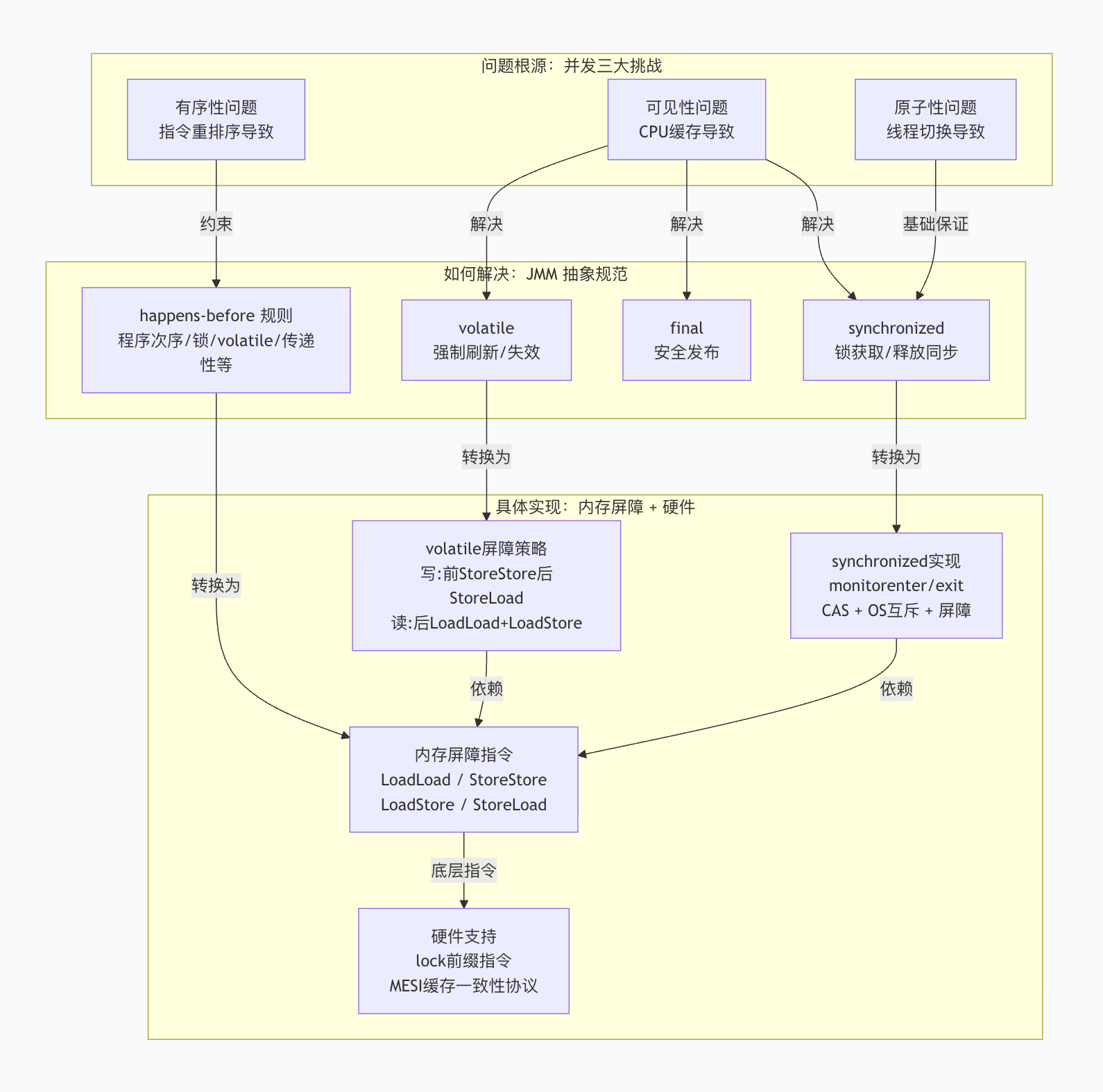
JMM是什么
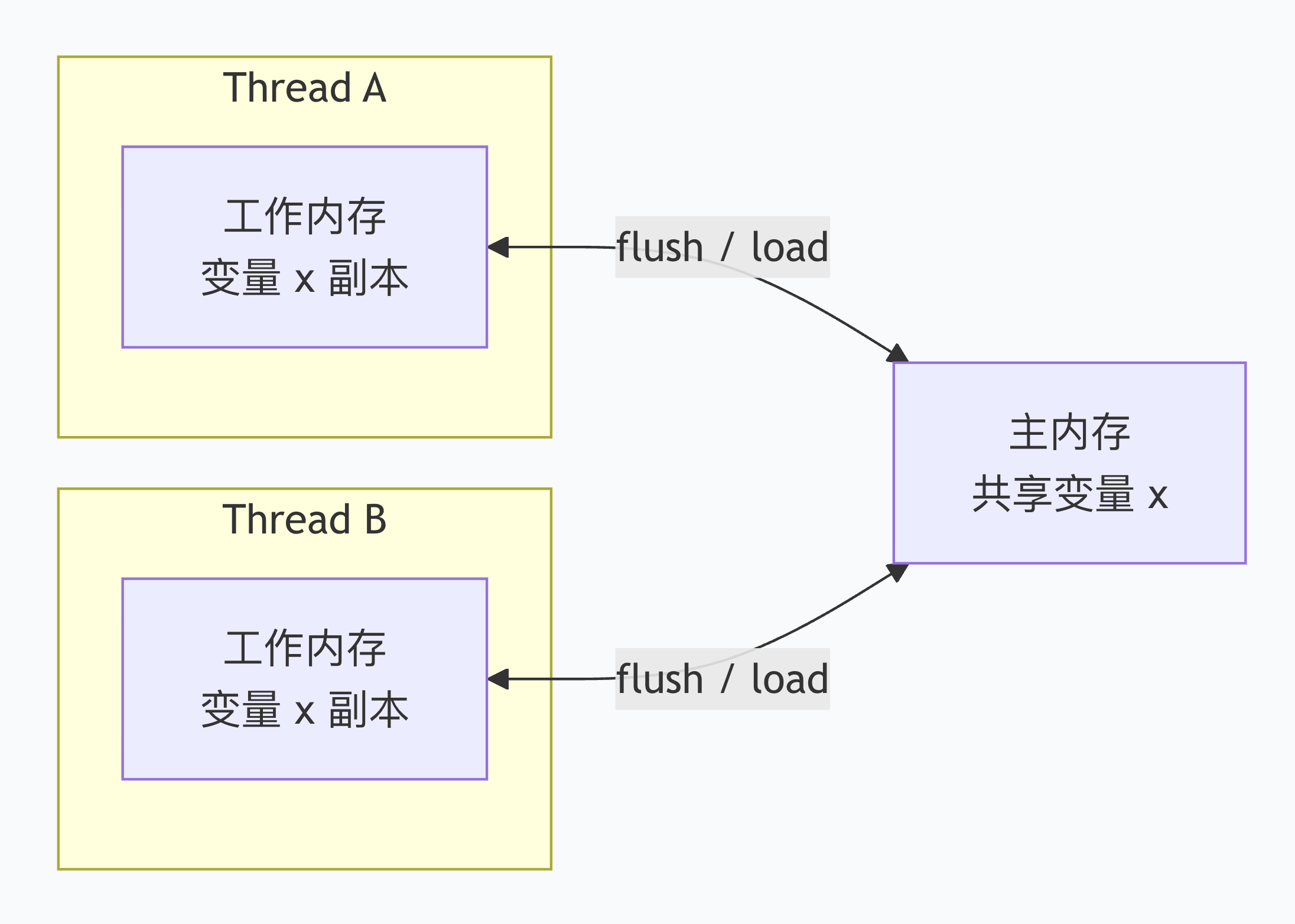
Java内存模型(Java Memory Model),简称JMM,是一套抽象的规范。定义了多线程环境中共享变量的访问规则。 JMM将内存划分为主内存和工作内存。
- 主内存:所有线程共享,存放变量的正式值。
- 工作内存:每个线程私有,存放该线程用到的主内存变量的副本。
JMM解决什么问题
JMM解决可见性、有序性两个问题:
- 可见性问题:CPU多级缓存与缓冲区。
- 有序性问题:编译器和处理器为了性能会进行指令重排序。
解决可见性
建立“强制刷新/失效”协议。JMM规定,线程对变量的操作不能一直停留在工作内存里,必须在特定时刻同步到主内存。
- volatile:
- 写操作:新值必须立即刷新到主内存。
- 读操作:每次读取前强制从主内存重新加载,并让其他线程的副本实效。
- synchronized:
- 加锁后:必须清空工作内存中变量副本,强制从主内存重新加载。
- 解锁前:工作内存的修改必须全部刷新到主内存。
- final:
- 只要构造期间没有让this引用逸出,构造完成后final字段的值对其他线程立刻可见,无需额外同步。
解决有序性
定义Happens-Before原则。规定哪些操作不可重排序。
保证基本的原子性
JMM只保证基本读写操作的原子性,除了long、double外,其他变量的单次读写操作都是原子的。复合操作必须通过锁或其他方式保证原子性。
JMM怎么实现
JMM的规范是抽象的, 需要靠JIT编译器插入内存屏障、处理器提供的硬件指令来落地。
内存屏障
JIT在编译字节码时,会在关键位置插入四种内存屏障指令。
| 屏障类型 | 作用 |
|---|---|
| LoadLoad | 禁止屏障前后的读操作重排 |
| StoreStore | 禁止屏障前后的写操作重排 |
| LoadStore | 禁止屏障前的读与屏障后的写重排 |
| StoreLoad | 禁止屏障前的写与屏障后的读重排(最重,同时具备其他三者效果) |
- volatile:
- 写操作:写前插入 StoreStore,写后插入 StoreLoad。
- 读操作:读后插入 LoadLoad 和 LoadStore。
- synchronized:使用字节码指令
monitorenter和monitorexit触发内存屏障,保证临界区内的读写在锁释放后可见。 - final:在构造方法末尾插入 StoreStore屏障,保证final字段赋值不会与对象引用赋值被重排序。
硬件指令
内存屏障主要通过CPU指令lock xxx实现。
- 强制将当前CPU缓存刷新到主内存。
- 通过MESI缓存一致性协议,将其他CPU缓存中对应数据失效。
- 阻止处理器对lock前后的指令进行重排序。
volatile
[!NOTE] volatile 最轻量的同步机制,通过写前StoreStore+写后StoreLoad、读后LoadLoad+LoadStore的内存屏障策略,保证多线程环境下的可见性和有序性,但不保证原子性。
- 可见性:
- 写入:volatile写后插入 StoreLoad屏障,强制将当前线程工作内存刷新到主内存。
- 读取:强制从主内存加载。
- 有序性:
- 写入:写前插入 StoreStore,写后插入StoreLoad。
- 读取:读后插入 LoadLoad、LoadStore。
synchronized
[!NOTE] synchronized 较重的同步机制,保证原子性、可见性、有序性。
synchronized用法:
- 修饰普通方法:锁当前实例对象this。
- 修饰静态方法:锁当前类对象。
- 修饰代码块:锁指定的对象。
如何保障的原子性、可见性、有序性:
- 原子性:锁互斥。同一时刻只有一个线程能进入临界区执行。
- 可见性:加锁后,工作内存被清空,强制从主内存重新加载;解锁前,强制刷新到主内存。
- 有序性:保证临界区内的代码不会与临界区外的代码发生重排序(即代码不能跨出或跨入临界区),但临界区内部的指令是允许重排序的。
底层实现原理:
- 字节码层:临界区代码由
monitorenter和monitorexit包裹,方法修饰符中设置了ACC_SYNCHRONIZED标志。确保同一时刻,只有一个线程能获取对象关联的Monitor。 - 对象头与Monitor:每个对象的对象头都有一个Mark Word,记录了锁状态(无锁、偏向锁、轻量级锁、重量级锁)。重量级锁状态下,Mark Word指向一个ObjectMonitor。
- 硬件层:原子性由CAS 或 操作系统互斥量保障。可见性和有序性由内存屏障保障。
锁升级:
- 无锁:没有加锁的情况下。
- 偏向锁:消除同一线程反复获取锁的同步开销。线程第一次获取到锁时,通过CAS在对象头的Mark Word记录下自己的线程ID。之后进入同步块,只需判断线程ID是否一致来确定是否是当前线程持有锁。
- 轻量级锁:并发情况下,通过CAS自旋来获取锁,获取成功后将对象头的Mark Word修改为指向当前线程在栈中创建的Lock Record。
- 重量级锁:自旋失败或竞争激烈时,膨胀为重量级锁。JVM创建ObjectMonitor,未获取到锁的线程进入等待队列,被操作系统挂起,直到锁释放后被唤醒。
final
[!info] final 解决不可变对象的安全发布问题。
核心保证是:当一个对象的构造函数执行完毕,且 this 引用没有在构造期间逸出,那么其他线程即使没有同步,也能立刻看到该对象中所有 final 字段的正确初始化值。
实现原理:在构造函数执行完毕、即将返回时,JIT 编译器插入了 StoreStore 内存屏障。确保在构造方法返回前,final变量已安全发布。
PS:只有包含final字段的构造方法,才会插入StoreStore屏障。
AQS
AQS,全称AbstractQueuedSynchronizer,是一个抽象的、基于FIFO等待队列的、用一个volatile ine表示同步状态的框架。
AQS解决的问题是:把线程如何安全地排队、阻塞、唤醒等这些复杂且容易出错的操作封装起来,让开发者只需关心何时加锁、何时释放的上层逻辑。
AQS使用模板方法模式定义:
- 线程如何安全地入队、出队。
- 如何用LockSupport.park/unpark挂起和唤醒线程。
- 如何处理中断和超时。
AQS数据结构:
- 状态变量state:表示同步状态,可以是重入锁或许可证。
- FIFO等待队列:一个由Node节点构成的双向链表,头节点表示当前持有锁或正在获取锁的线程。
- 等待状态waitStatus:每个Node节点有一个waitStatus。
- SIGNAL(-1):表示后继节点需要被唤醒。当前节点释放锁时,必须检查并unpark后继节点。
- CANCELLED(1):节点因超时或中断被取消。
AQS的两种获取锁模式:
- 独占模式:
- 核心特征:同一时刻只有一个线程能成功获取资源。
- 典型实现:ReentrantLock。
- 状态变量state含义:锁支持次数(0=空闲,1=持有,>1=重入)。
- 共享模式:
- 核心特征:同一时刻多个线程可以同时成功获取资源。
- 典型实现:Semaphore、CountDownLatch。
- 状态变量state含义:剩余许可证/资源数量。

ReentrantLock、Semaphore、CountDownLatch等都是基于AQS实现的。
ReentrantLock
[!NOTE] 锁模式 独占模式
ReentrantLock是一个可重入的互斥锁,内部有一个继承自AQS的Sync,并分为公平锁和非公平锁两种实现,默认为实现为非公平锁。
加锁逻辑:
- lock():调用acquire(1)
- tryAcquire(1):
- 若state等于0,则CAS获取锁,成功则设为锁持有者。
- 若当前线程已是持有者,则state+1,表示重入。
- 若CAS失败,则进入等待队列。
解锁逻辑:
- unlock():调用release(1)
- tryRelease(1):state-1,若state清零,则释放锁,并唤醒后继节点。
两种锁实现:
- 公平锁:先检查队列里有没有线程在等,有就乖乖排队。
- 非公平锁:一上来就CAS抢锁,不看队列里有没有线程排队。
Semaphore
[!NOTE] 锁模式 共享模式
Semaphore是信号量,将state表示为剩余许可证数量,来控制多个线程访问资源。内部有一个继承自AQS的Sync,并分为公平锁和非公平锁两种实现,默认为实现为非公平锁。
加锁逻辑:
- acquire():调用acquireSharedInterruptibly(1)
- tryAcquireShared(1):
- 若state大于0,CAS更新state-1,表示当前线程获取一个许可。
- 若state小于0,返回负数,进入等待队列。
解锁逻辑:
- release():调用releaseShared(1)
- tryReleaseShared(1):CAS更新state+1,表示归还一个许可。
若剩余许可证数量大于0,AQS会自动唤醒下一个等待的线程,直到许可证为0。
CountDownLatch
[!NOTE] 锁模式 共享模式
CountDownLatch是倒计时门闩,将state表示为还需等待的事件数量,是一个一次性的共享模式实现。
加锁逻辑:
- await():调用acquireSharedInterruptibly(1)
- tryAcquireShared(1):
- 若state等于0,直接放行。
- 若state大于0,则进入等待队列。
解锁逻辑:
- countDown():调用releaseShared(1)
- tryReleaseShared(1):CAS更新state-1,当state等于0,释放锁成功,并触发唤醒。
Semaphore和CountDownLatch的关键区别:
- Semaphore:state可复用。
- CountDownLatch:state是一次性的,当state等于0,所有等待线程被唤醒,门闩永久打开。
AQS实现比对
| 特性 | ReentrantLock | Semaphore | CountDownLatch |
|---|---|---|---|
| 模式 | 独占 | 共享 | 共享 |
| state 含义 | 锁持有次数 | 剩余许可证数 | 还需等待的事件数 |
| 获取 | lock() → state 0→1 |
acquire() → state 减 N |
await() → 等 state==0 |
| 释放 | unlock() → state 减 1 |
release() → state 加 1 |
countDown() → state 减 1 |
| 可重入 | ✅ | ❌ | ❌ |
| 锁支持 | 公平锁/非公平锁 | 公平锁/非公平锁 | ❌无此概念 |
| 复用性 | 可复用 | 可复用 | 一次性 |
| 唤醒传播 | 无(独占) | 有(共享) | 有(共享,到 0 时) |
ThreadLocal
ThreadLocal是一个线程级别的隔离工具。每个线程有一份独立的存储,可以避免线程间的数据共享和竞争。
核心原理:每个Thread对象有一个ThreadLocalMap。ThreadLocalMap是一个哈希表,key为ThreadLocal对象(弱引用),value为需要存储的值。
key为什么设计为弱引用? 为了在ThreadLocal对象失去外部引用后,key可以被GC回收。这样ThreadLocalMap里的key为null,但value还被强引用。所以必须通过remove来清理,防止内存泄漏。
线程池
线程池是一种池化资源技术,它预先创建一定数量的线程,放入“池子”中。当有任务需要执行时,从池子里取一个线程来执行,任务执行完成后线程不会销毁,而是返回池子等待下一个任务。
为什么需要线程池?
- 降低资源消耗:避免频繁创建、销毁线程的开销。
- 提高响应速度:任务到达时,无需等待线程创建就可以立即执行。
- 提高线程的可管理性:可以统一分配、调优和监控线程的数量和状态。
ThreadPoolExecutor
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)ThreadPoolExecutor是线程池的核心实现类,提供了以下参数:
- corePoolSize:核心线程数,即使空闲也不会回收。
- maximumPoolSize:线程池允许的最大线程数。
- keepAliveTime:当线程池大于核心线程数时,多余空闲线程的存活时间。
- unit:存活时间的单位。
- workQueue:线程等待队列。
- threadFactory:线程工厂,可以自定义线程名称。
- handler:拒绝策略,当队列满且达到最大线程数时,拒绝线程的策略。
线程池执行流程
- 若 当前线程数 < 核心线程数,则创建核心线程执行。
- 若 当前线程数 = 核心线程数,且队列未满,则将线程放入等待队列。
- 若 队列已满,但当前线程数 < 最大线程数,则创建非核心线程执行。
- 若 队列已满,且当前线程数 >= 最大线程数,则执行拒绝策略。
核心线程数是常驻线程,最大线程数是临时的救急线程。
Executors
Executors是JUC包中的一个线程池工厂类,用于快速创建ExecutorService实例。
Executors默认提供了几个工厂方法:
- newFixedThreadPool:
- 线程池介绍:固定大小的线程池。
- 核心线程数:指定大小。
- 最大线程数:指定大小。
- 等待时间:0
- 等待队列:无界队列LinkedBlockingQueue。
- newCachedThreadPool
- 线程池介绍:缓存线程池。
- 核心线程数:0。
- 最大线程数:无限大。
- 等待时间:60s。
- 等待队列:无容量队列SynchronousQueue。
- newSingleThreadExecutor:
- 线程池介绍:单个线程的线程池。
- 核心线程数:1。
- 最大线程数:1。
- 等待时间:0。
- 等待队列:无界队列LinkedBlockingQueue。
- newScheduledThreadPool:
- 线程池介绍:定时调度线程池。
- 核心线程数:指定大小。
- 最大线程数:无限大。
- 等待时间:10s。
- 等待队列:延迟队列DelayedWorkQueue。
《阿里巴巴 Java 开发手册》规定:不允许使用 Executors 创建线程池,必须通过 ThreadPoolExecutor 手动创建。
使用默认线程池工厂方法的风险:
- OOM:等待队列无限大,可能发生OOM。
- 资源耗尽:最大线程数无限大,可能导致资源耗尽。
等待队列
线程池使用的队列全部来自 java.util.concurrent.BlockingQueue接口的实现:
- ArrayBlockingQueue:数组阻塞队列,有界,必须指定容量。
- LinkedBlockingQueue:线性阻塞队列,默认无界,可指定有界。
- SynchronousQueue:同步阻塞队列,无容量,直接提交。
- PriorityBlockingQueue:优先级阻塞队列,无界,按优先级提交。
- DelayedWorkQueue:延迟阻塞队列,无界,延迟提交。
ArrayBlockingQueue和LinkedBlockingQueue的区别:
- 内存占用控制:ArrayBlockingQueue的内存占用更可控一些,可以指定大小,避免任务堆积。
- 吞吐量:ArrayBlockingQueue使用单锁,LinkedBlockingQueue:双锁,吞吐量高。
- 灵活性:对任务量变化较大的应用场景,LinkedBlockingQueue更灵活。
拒绝策略
当队列已满且达到最大线程数时,触发拒绝策略。
拒绝策略:
- AbortPolicy:默认拒绝策略,直接抛出RejectedExecutionException异常,需要处理异常。
- CallerRunsPolicy:由调用者执行任务。
- DiscardPolicy:直接丢弃新任务,不会抛出异常。
- DiscardOldestPolicy:丢弃队列中最老的任务。
线程池配置最佳实践
- CPU密集型任务:以计算为主,线程数 = CPU核心数 + 1。
- IO密集型任务:大量阻塞等待,线程数 = CPU核心数 * 2,或更精准的计算方式:CPU核心数 * (1+平均等待时间/平均计算时间)。
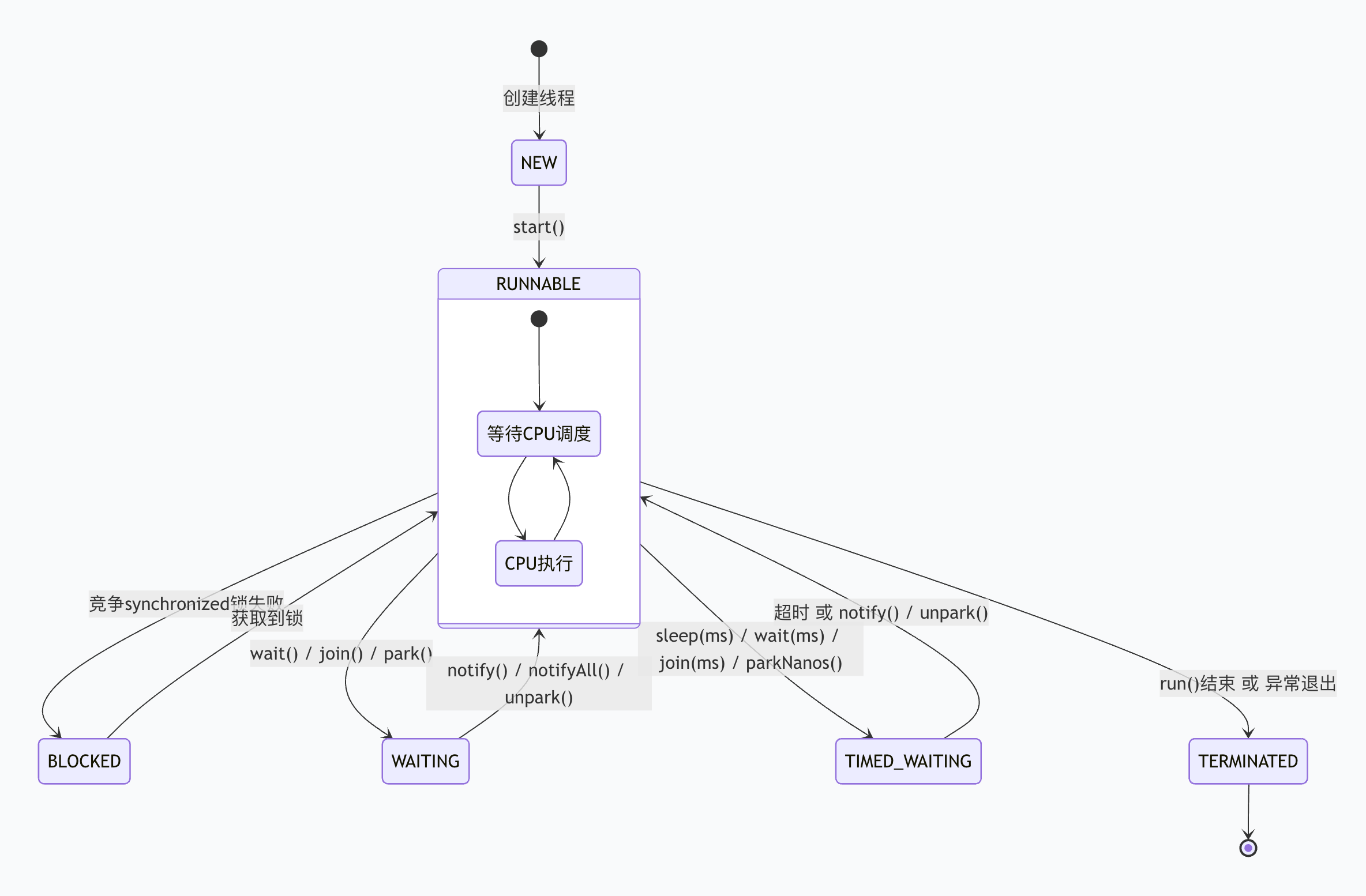
线程生命周期
- NEW:线程刚创建,尚未启动。
- RUNNABLE:可运行状态(包含等待调度和已抢占到时间片两种情况)。
- BLOCKED:获取锁被阻塞,仅限synchronized锁。
- WAITING:无限期等待直到被唤醒。常见如:ReentrantLock使用LockSupport.park()来阻塞线程、wait()、join()。
- TIMED_WAITING:限时等待,超时自动返回。
- TERMINATED:线程执行完毕或异常退出。