JVM
JVM是什么
JVM是Java虚拟机,解决的核心问题是一次编写,到处运行。JVM通过在操作系统之上建立一个抽象的计算机,让字节码文件可以跨平台执行。
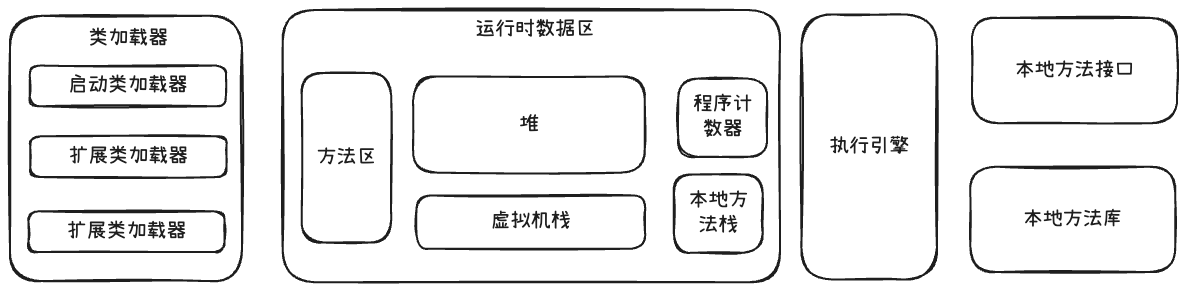
JVM组成结构
- 类加载器:加载字节码文件到内存,进行加载、链接、初始化操作,生成对应的Class对象。
- 运行时数据区:JVM的内存管理区域,包含共享区域(堆、方法区)、线程私有区域(虚拟机栈、本地方法栈、程序计数器)。
- 执行引擎:将字节码翻译为操作系统可以执行的机器指令,包含解释器、JIT编译器两种方式。
- 本地方法接口(JNI):一套标准接口,允许Java代码调用c/c++等语言实现的本地方法。
- 本地方法库:用c/c++等编写并编译好的动态链接库,提供Java无法直接完成的系统级操作,通过JNI被JVM加载和调用。
类加载机制
一个类的生命周期:加载 -》 验证 -》准备 -》解析》初始化 -》使用 -》卸载
双亲委派模型是类加载机制的核心,当一个类加载器收到加载请求时,自己不先尝试加载,而是逐级向上委派给父加载器,直到最顶层的Bootstrap ClassLoader。只有父加载器无法加载该类时,子加载器才尝试加载。
- 启动类加载器:Bootstrap ClassLoader。
- 扩展类加载器:Extension ClassLoader。
- 应用类加载器:Application ClassLoader。
为什么需要双亲委派模型?
- 安全:保证Java核心类库由启动类加载器加载,避免被篡改。
- 唯一:优先交给父加载器加载,避免重复加载。
如何打破双亲委派模型?
通过自定义类加载器,打破“父加载器无法直接加载子加载器可见类”。
实现方式:每个线程都有一个contextClassLoader,默认是应用类加载器。核心库的代码通过Thread.currentThread().getContextClassLoader()拿到线程上下文加载器,然后用它来加载子类,从而打破“父加载器无法直接加载子加载器可见类”。
类的生命周期:
- 加载:根据全限定名找到字节码,在堆中生成
Class对象。 - 验证:检查字节码是否安全合规,防止恶意代码。
- 准备:为静态变量分配内存并赋予默认值。普通静态变量设置为0、null或false,编译器静态变量(static final修饰的基本类型或String类型)设置为代码中指定值。
- 解析:把符号引用转成能直接定位的内存引用,如类引用、方法引用等。
- 初始化:执行类的构造器方法,为静态变量赋值、执行静态代码块。
- 使用:程序通过
Class对象创建实例或调用方法。 - 卸载:该类的
Class对象被回收,方法区数据清除。
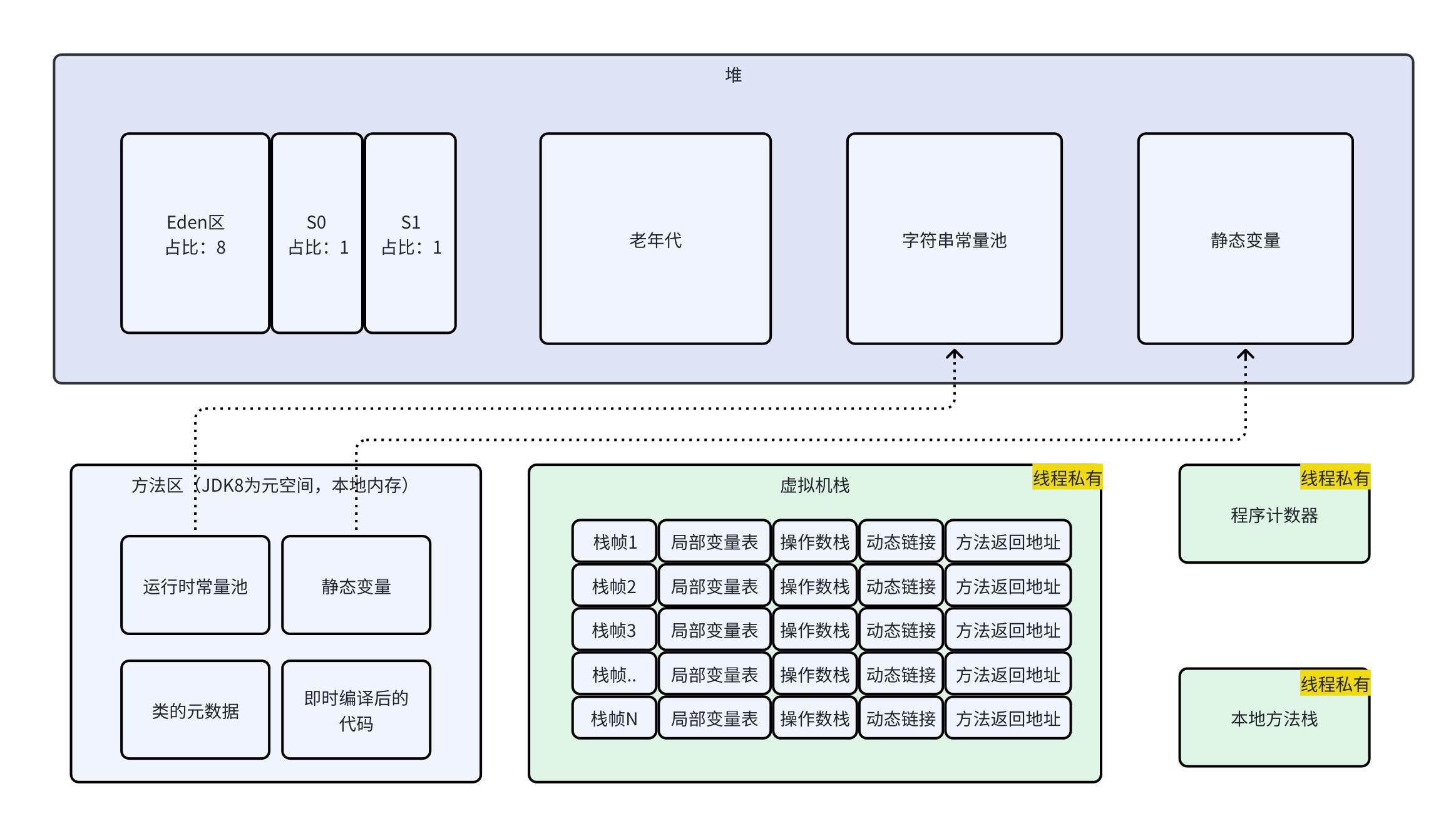
运行时数据区
运行时数据区是JVM的内存管理区域,规定了程序在运行时的数据该放在哪里、由谁共享、何时创建销毁等。
堆
[!NOTE] 线程安全 线程共享
JVM中最大的一块内存,几乎所有对象实例都在此分配。从GC视角,堆采用分代设计,将内存分为:
- 新生代:包含Eden区和两个Survivor区,比例为:8:1:1。绝大多数对象诞生在Eden区,熬过垃圾回收的对象会晋升到Survivor区,再从Survivor区晋升到老年代(每熬过一次Minor GC,则对象的GC年龄+1,达到默认值15时,晋升到老年代)。
- TLAB:线程本地分配缓冲区,全称:Thread Local Allocation Buffer。TLAB是JVM为加速多线程下对象分配而设计的核心优化,在Eden区为每个线程划分一块独享空间,让线程在自己的独享空间内分配内存,与其他线程互不干扰。
- 老年代:存放长期存活对象,如缓存、数据库连接池等。
因为大部分对象都“朝生夕死”,所以在不同生命周期的对象采用不同的垃圾回收算法。新生代大部分对象生命周期较短,适合标记复制算法。老年代对象生命周期相对较长,适合标记整理或标记清除算法。
对象分配流程:
- 线程创建对象,先检查TLAB剩余空间是否足够,足够则直接在TLAB内指针碰撞,完成分配。
- 若TLAB剩余空间不够:
- 申请新TLAB分配:申请一块更大的TLAB,在新TLAB分配。
- 在Eden区分配:对象大小适中,但新申请TLAB不划算,则在Eden区的公共区域通过同步操作分配。
- 在老年区分配:对象较大,则跳过Eden区,直接在老年代分配,避免在新生代频繁复制。
方法区
[!NOTE] 线程安全 线程共享
存储类的元数据、运行时常量池、静态变量、JIT编译后的代码缓存等。
- 类的元数据:存放类的全限定名、字段描述、方法描述等。
- 运行时常量池:存放字面量和符号引用。(动态链接就靠它)
- 静态变量:static修饰的变量。从JDK1.7起,字符串常量池和静态变量从原来的方法区移动到了堆中,但逻辑上还是方法区。
- JIT编译后的代码缓存:热点方法被JIT编译称本地机器码后,缓存在方法区。
演变历史:
- JDK1.7:在堆内实现为永久代,容易OOM。
- JDK1.8:改为使用本地内存的元空间,可以直接使用本地系统内存,仅受物理内存限制。同时,原来在永久代的字符串常量池和静态变量转移到了堆中。
虚拟机栈
[!info] 线程安全 线程私有
每个线程创建时,JVM会为其分配一个私有的虚拟机栈,内部由一个个栈帧组成。每个方法被执行时,都会创建一个栈帧入栈,方法结束后出栈。
栈帧的结构:
- 局部变量表:存放方法参数和局部变量,以槽位Slot为最小单位。
- 操作数栈:一个后进先出的栈,用于计算的临时工作区。例如计算 int a = 1+2; 先压入1、2,执行iadd指令相加,结果放回栈顶,再存入局部变量表。
- 动态链接:指向方法区中的运行时常量池对该方法的符号引用,并替换为直接引用。(多态)
- 方法返回地址:记录方法调用后的下一条指令地址,正常退出或异常退出都要恢复调用者现场。
栈常见错误:
- StackOverFlowError:栈溢出,通常由于方法递归深度太大导致。
- OutOfMemoryError:栈无法申请足够内存时。
程序计数器
[!info] 线程安全 线程私有
程序计数器是当前线程所执行的字节码行号指示器,CPU时间片在各线程间切换,每个线程都有自己的“进度条”。
- 当线程正在执行一个Java方法,程序计数器记录的是当前字节码指令的地址。
- 当线程正在执行一个Native方法,程序计数器的值为空。
为什么需要程序计数器?
- 流程控制:字节码指令执行时,解释器根据计数器取下一行指令。
- 线程恢复:多线程抢占CPU时,任何线程被挂起后再恢复,是程序计数器来告诉线程“上一次执行到哪一行”的。
- 异常处理:抛出异常时,JVM通过当前计数器位置查找异常表,确定该在哪一行catch。
本地方法栈
[!info] 线程安全 线程私有
本地方法栈是为Native方法调用服务的栈,它让c、c++代码能在JVM内部安全运行。通过JNI,Java可以调用c、c++实现的函数,而本地方法栈就为这些Native方法提供栈环境。
执行引擎
执行引擎是JVM的心脏,它负责把字节码翻译成操作系统能执行的机器指令并运行。但为了既快又灵活,采用了“解释执行+编译执行”混合驱动的设计。
执行引擎组成部分:
- 解释器:逐条将字节码翻译为本地机器指令并执行。类比:同声传译。
- JIT编译器:将热点代码一次性编译成本地机器码,后续直接运行。类比:翻译后的文字稿。
- 垃圾回收器:严格说垃圾回收器也属于执行引擎的一部分,负责自动内存回收。
为什么要用解释器+JIT编译器混合模式? 为了找到一种性能平衡,所以采用了混合模式:
- 解释器:负责“预热”、“兜底”。程序刚启动时,快速响应。当JIT编译失败时,退回解释执行保证正确性。
- JIT编译器:负责“加速”。收集到足够热点信息后,对真正的性能瓶颈进行深度优化。 这也是说Java是编译和解释共存的原因。
如何识别热点代码? HotSpot采用热点探测, 主要基于计数器:
- 方法调用计数器:记录每个方法被调用的次数。
- 回边计数器:记录循环体执行的次数。热点循环会触发OSR(栈上替换),将正在解释执行的循环替换为编译好的机器码。 需注意,为避免临时热点代码造成的资源浪费,计数器会随时间进行半衰减的“降温”,只保留高频使用的热点代码。
JIT编译器采用分层编译,C1快速预热+收集数据 -》C2精准优化。
- C1编译器:编译速度快,生成代码质量中等,适合需要快速处理的短任务。
- C2编译器:编译耗时长,但会进行大量基于运行时信息的激进优化(如逃逸分析、方法内联)等,生成代码执行效率极高,适合长时间运行的服务器应用。
JVM垃圾回收
垃圾回收(Garbage Collection),简称GC,是JVM自动管理内存的机制。它会自动识别不再使用对象,并释放它们占用的空间。
GC解决的核心问题
- 提高系统健壮性:把内存管理的负担从人交给机器,让程序不会因忘记释放内存而慢慢撑爆。
- 支撑“一次编写,到处运行”:内存管理交给JVM,是跨平台保障的一部分。
核心矛盾:GC时必须暂停用户线程,即STW。因为不能在一个正在变化的对象关系图上找垃圾。GC的进化史,都是在让STW时间更短、更可控。
寻找垃圾的两种方式
- 引用计数法(Java不用):每个对象有一个计数器,有引用则+1,引用失效则减1,引用为0则表示可以回收。但存在循环引用问题时会导致永远无法回收。
- 可达性分析(Java采用):从一组GC Roots根对象出发,沿着引用链搜索。不在引用链上的对象,就是不可达对象,表示可以回收。
GC Roots对象:
- 虚拟机栈(栈帧中局部变量表)引用的对象
- 方法区中静态变量引用的对象
- 方法区中常量引用的对象
- 本地方法栈中JNI引用的对象
- 所有被同步锁持有的对象
四种引用类型
不是所有引用都希望永远绑着对象不放,有时我们希望对象在内存紧张时可以被回收,有时可能只想跟踪对象是否被回收了。 这四种引用不是改变可达性分析的根,而是定义了引用强度的等级。
| 引用类型 | GC回收策略 | 何时回收 | 典型用途 |
|---|---|---|---|
| 强引用 | 永不回收 | —— | 最普通的对象引用 |
| 软引用 | 内存不足时回收 | 即将OOM | 内存敏感的高速缓存 |
| 弱引用 | GC时必定回收 | 下一次GC | WeakHashMap、ThreadLocal |
| 虚引用 | 任何时候,仅收通知 | 对象被回收时通知 | 管理堆外内存(DirectByteBuffer) |
强引用:
常见的对象引用都是强引用,例如Object o = new Object。
软引用:SoftReference 用SoftReference包裹对象,当系统内存充足时,GC不会回收。当内存不足即将OOM时,JVM会把软引用对象全部回收。
弱引用:WeakReference 用WeakReference包裹对象,一旦GC发生,不管内存是否充足,弱引用指向的对象必定被回收。它的生命周期只存活到下一次GC前。
- 典型用途:ThreadLocal中的ThreadLocalMap的key是ThreadLocal对象,是弱引用。
虚引用:PhantomReference 用PhantomReference包裹对象,get永远返回null。它的唯一作用是:当指向的对象被GC回收时,虚引用会被放入关联的ReferenceQueue中,起到通知作用。
常见垃圾回收算法
- 标记-清除:先标记,再统一清除。缺点是会产生内存碎片。
- 标记-复制:把内存分两块,用一块,存活的对象复制到另一块。整体清空当前块。解决了内存碎片问题,但造成空间浪费。
- 标记-整理:标记后,让存活对象往一端移动,直接清理边界外的内存。
常见垃圾回收器
| 收集器 | 作用区域 | 算法 | 线程模型 | 核心目标 |
|---|---|---|---|---|
| Serial | 新生代 | 标记-复制 | 单线程 | 简单高效,Client模式首选 |
| ParNew | 新生代 | 标记-复制 | 多线程 | Serial的多线程版,配合CMS |
| Parallel Scavenge | 新生代 | 标记-复制 | 多线程 | 吞吐量优先 |
| Serial Old | 老年代 | 标记-整理 | 单线程 | 配合Serial,CMS后备 |
| Parallel Old | 老年代 | 标记-整理 | 多线程 | 配合Parallel Scavenge |
| CMS | 老年代 | 标记-清除 | 多线程 | 最短停顿时间 |
| G1 | 全堆 | 混合(复制+整理) | 多线程 | 可预测的停顿时间 |
CMS
[!NOTE] 介绍 CMS是一款老年代垃圾收集器,核心目标是收集老年代的垃圾。在JDK9被废弃、JDK14彻底移除。
核心原理:基于标记-清除算法,把最耗时的标记过程交给GC线程和用户线程并发执行,只在无法并发的关键节点短暂STW。
执行阶段:
| 阶段 | STW? | 做什么 | 耗时 |
|---|---|---|---|
| 初始标记 | 是 | 只标记 GC Roots 直接关联的对象 | 极短 |
| 并发标记 | 否 | 从直接关联对象出发,遍历整个对象图,并通过卡表标记脏页。 | 长 |
| 并发预清理 | 否 | 提前扫描卡表脏页并尽量尽量等待一次Minor GC,为重新标记阶段减负。 | 长 |
| 重新标记 | 是 | 修正并发标记期间因用户线程运行而变动的标记 | 较短 |
| 并发清除 | 否 | 清理垃圾对象 | 长 |
CMS的三色标记法:
- 白色:未被扫描过的对象,标记结束后,白色为可回收对象。
- 灰色:对象本身已被访问,但它引用的子对象还没扫描。
- 黑色:对象及其所有子引用全部扫描完毕,是确定存活的对象。
标记过程:
- 在初始标记阶段,STW。从GC Roots出发,把直接关联的对象标记为灰色。
- 在并发标记阶段,从标记为灰色的对象出发,把自身标记为黑色。然后扫描它引用的对象,标记为灰色。如此,层层扫描。
- 因用户线程也在执行,CMS会通过写屏障+卡表记录哪些对象的引用发生了变化,在赋值指令后立即执行:找到卡页,并标记为脏页。写屏障是记录动作,卡表是记录结果。
- 并发预清理:主动扫描卡表中的脏页,把其中涉及的对象重新扫描和标记,尽可能的修复漏标。
- 可终止的并发预清理:尽量等待一次Minor GC,减少重新标记阶段需要扫描的新生代对象。
- 在重新标记阶段,STW。重新扫描 新生代中所有存活对象、GC Roots、卡表中所有仍为脏页的。
卡表介绍: 卡表是一个位图(bitmap),将整个堆内存按固定大小(通常为512字节)划分为卡页。每个卡页对应卡表中的一个位。当这个位置被标记为1,表示这个卡页脏了。
G1
[!NOTE] 介绍 G1,Garbage-First,优先回收价值最高的垃圾,在JDK9成为默认垃圾回收器。追求目标是:在可控的停顿时间内,获得尽可能高的吞吐量,特别适合大堆。
G1把整个堆分成大小相等的Region,默认约2048个,每块1-32MB,取2的幂次。 每个Region可以在不同时间扮演不同的角色:
- Eden:新生代
- Survivor:S0、S1
- Old:老年代
- Humongous:巨型对象,当一个对象超过Region的一半大小时,被视为巨型对象。
核心目标:G1会根据历史数据,推测回收一个Region需要的时间,然后在此次停顿时间内,只回收预估可以完成的价值最高的Region。可以通过-XX:MaxGCPauseMillis设定停顿时间。
标记阶段:
- 初始标记:伴随Minor GC,标记GC Roots直接关联对象,因为Minor GC会将新生代的活对象复制到Survivor区。所以就以Survivor Region作为根区间。
- 根区间:扫描所有Survivor Region,找出所有Survivor -》老年代的引用,为后续并发标记提供老年代入口。
- 并发标记:使用STAB快照,通过写前屏障将被删除的引用记录到STAB队列。全程并发,会产生浮动垃圾。
- 最终标记:处理STAB队列中剩余的引用变更,完成最终标记修正。STW极短。
STAB:开始标记前,先拍个快照。并发标记期间只要有引用断开,就把断开前指向的那个对象记下来并标记为灰色。宁可多留一些浮动垃圾,也绝不错回收。
RSet:Remembered Set,是每个Region的备忘录,专门记录其他Region中的哪些卡页引用了本Region内的对象。把这些跨Region的引用维护好,在回收一个Region时,只扫描与他相关的其他Region即可,而不是整个堆。
回收类型:
- Minor GC:当Eden区满后,把活对象复制到新的urvivor或晋升到老年代Region。
- Mixed GC:当老年代堆占用达45%后,G1会启动一个并发标记周期,计算出每个老年代Region的垃圾比例,然后选取垃圾最多的老年代Region和所有年轻代Region一起回收。Mixed GC分多次进行,每次回收一小批。
- Full GC:当对象分配过快,或巨型对象无法找到空间分配,则会退化为Serial Old单线程收集,会导致较长时间的STW。
GC调优
FAQ
为什么说Java是解释和编译并存?
Java同时采用解释执行和编译执行(JIT即时编译),是一种性能优化平衡策略,保证启动速度和执行效率。
- 解释器:逐行翻译字节码为机器码,并立即执行,不会保存结果。类比:同声传译。
- 编译器:针对热点代码进行一次性的完整翻译,并保存结果,后续直接复用。类比:翻译后的文字稿。